OpenRE devlog 0 : Oracle Driven Development
Table des matières
Introduction
Bienvenue dans ce tout premier devlog d’OpenRE : le devlog zéro ! Cette série a pour but de documenter la phase de proof of concept (POC) du projet.
Si vous ne l’avez pas encore lu, je vous recommande de consulter l’article Les prémices d’OpenRE (Open Retro Engine), qui vous donnera une vision globale du projet. J’y introduis notamment quelques notions et un peu de terminologie. Il est préférable de l’avoir parcouru pour mieux contextualiser ce que je raconte dans les devlogs.
Dans ce numéro, je vais parler de méthodologie. Nous allons mettre en place un petit outil qui nous aidera à harmoniser les données dont OpenRE a besoin pour fonctionner. Mais avant d’entrer dans le vif du sujet, laissez-moi introduire un peu de contexte.
1. Format de la série
Tout au long du développement, je prendrai des notes dès que je tomberai sur un sujet intéressant. Chaque mois (si j’arrive à m’y tenir), je sélectionnerai les plus pertinents pour les présenter dans un ou plusieurs nouveaux numéros, si j’estime que les séparer a du sens.
Étant donné qu’OpenRE est un projet personnel que je développe sur mon temps libre, le rythme de publication risque d’être irrégulier. Certains mois seront plus légers que d’autres, mais ce n’est pas bien grave. Au contraire, ce sera intéressant de voir comment la cadence évolue au fil du temps.
2. Shit happens
Petite particularité concernant les premiers articles de la série : il s’agira de rétro-devlogs. En effet, j’ai démarré ce projet il y a déjà plusieurs mois, sans trop savoir où j’allais. Je n’étais pas sûr que mes expérimentations mèneraient quelque part et, de toute façon, l’idée même de tenir un blog ne m’avait pas encore traversé l’esprit.
Durant cette période, il se trouve que le dépôt Git a pris feu (suite à une sombre histoire de fichiers Blender beaucoup trop volumineux). Je sais qu’il existe des méthodes douces pour régler ce genre de problème, mais j’avoue que, sur le moment, je ne voyais pas trop l’intérêt. J’ai donc bêtement supprimé le dépôt pour en recréer un avec ma copie locale (après avoir fait le nécessaire pour mieux gérer mes scènes).
 Image générée par IA d’un dépôt Git sinistré par un fichier Blender trop gros
Image générée par IA d’un dépôt Git sinistré par un fichier Blender trop gros
Résultat : j’ai perdu l’historique du projet. Je ne peux donc plus restaurer les premières versions pour analyser ce que j’avais fait. Réaliser des captures d’écran de mes résultats originaux est également impossible. Ces premiers numéros seront donc des reconstitutions.
Part I : Problématique de l’harmonisation des données
Si vous avez lu l’article mentionné dans l’introduction, vous savez qu’OpenRE permet de fusionner le rendu de deux scènes :
- La scène déterministe : précalculée dans Blender
- La scène interactive : rendue en temps réel dans Godot
Pour cela, la technologie s’appuie sur une structure de données particulière appelée un G-Buffer. Pour rappel, il s’agit d’une collection de textures encodant diverses données géométriques relatives à un point de vue d’une scène (profondeur, albédo, normales, etc.).
Pour fusionner les scènes, OpenRE va donc composer les G-Buffers déterministe et interactif (respectivement générées par Blender et Godot). Mais il n’est pas évident que des données produites par deux logiciels différents soient directement compatibles. C’est même loin d’être gagné.

En effet, tous les logiciels graphiques suivent des conventions qui leur sont propres (unités, espaces colorimétriques, axes du repère, etc.). Tant qu’on reste à l’intérieur d’un système, la cohérence de l’ensemble est plus ou moins garantie. Mais dès lors que deux systèmes doivent s’échanger des données pour collaborer, c’est le début des problèmes.
Avant toute chose, il va donc falloir s’arranger pour que Blender et Godot parlent la même langue. Et comme on le verra dans les prochains devlogs, cela va demander un certain nombre d’ajustements.
Part II : La méthode de l’oracle
Pour identifier ces ajustements, on va utiliser une technique que j’aime bien et que j’appelle le Oracle Driven Development. C’est un peu comme du Test Driven Development, sauf qu’au lieu d’avoir un jeu de tests automatisés, propre et exhaustif, on va bricoler une petite moulinette qu’il faudra lancer en partie à la main.
À la manière d’un oracle, cette moulinette va formuler des prophéties parfois cryptiques en réponse aux questions qu’on lui pose. Mais interprétés correctement, ces présages nous aideront à avancer dans notre périple.
1. Comment ça marche ?
Si Godot et Blender sont bien sur la même longueur d’onde, les G-Buffers qu’ils produisent à partir d’une même scène devraient être identiques. C’est ce que nous allons chercher à vérifier avec l’aide de l’oracle. Son rôle sera de comparer les G-Buffers qu’on lui donne et de nous délivrer une image à partir de laquelle on devra déduire son verdict.
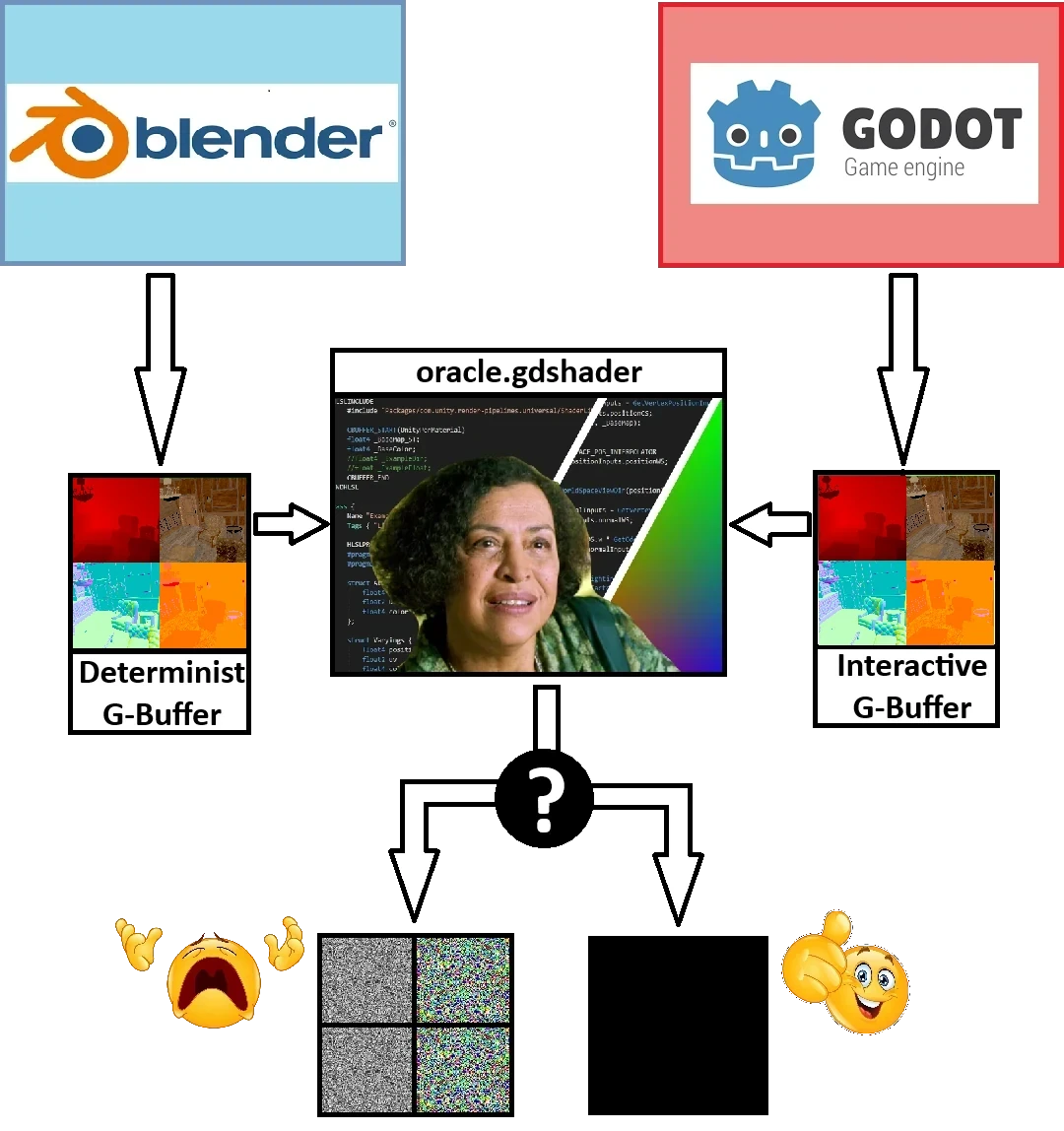
Mais trêve de métaphores. Concrètement, cet oracle est un post-process du nom de oracle.gdshader. Il prend en entrée :
- les textures des deux G-Buffers
- le type de texture à comparer
Son job est de calculer, deux à deux, les différences entre les textures déterministe et interactive de chaque type et d’afficher à l’écran celle qui correspond au type sélectionné. Le degré de différence sera représenté en niveaux de gris :
- Noir → les pixels des textures sources sont identiques
- Blanc → la différence entre les pixels des textures sources est maximale
Si l’oracle affiche une image entièrement noire pour chaque type de texture, c’est gagné : les G-Buffers sont identiques.
2. Mise en place d’une scène de test
Pour commencer, j’ai créé une petite scène dans Blender, composée de quelques primitives et d’une caméra. Ensuite, je l’ai reproduite à l’identique dans Godot. L’opération est triviale, étant donné que Godot prend en charge le format de scène de Blender. Il suffit d’importer le fichier .blend et de l’ajouter à une scène vide.
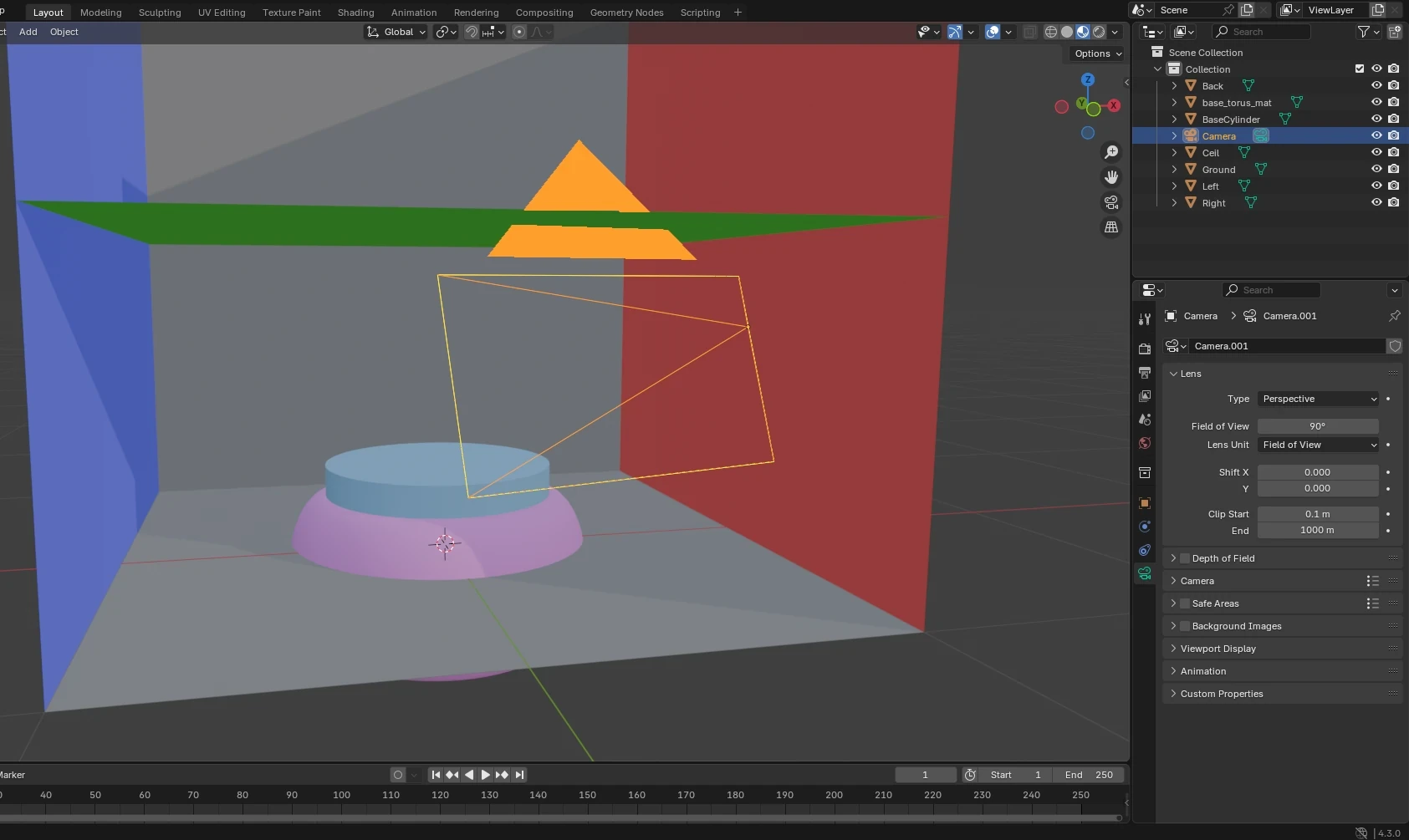
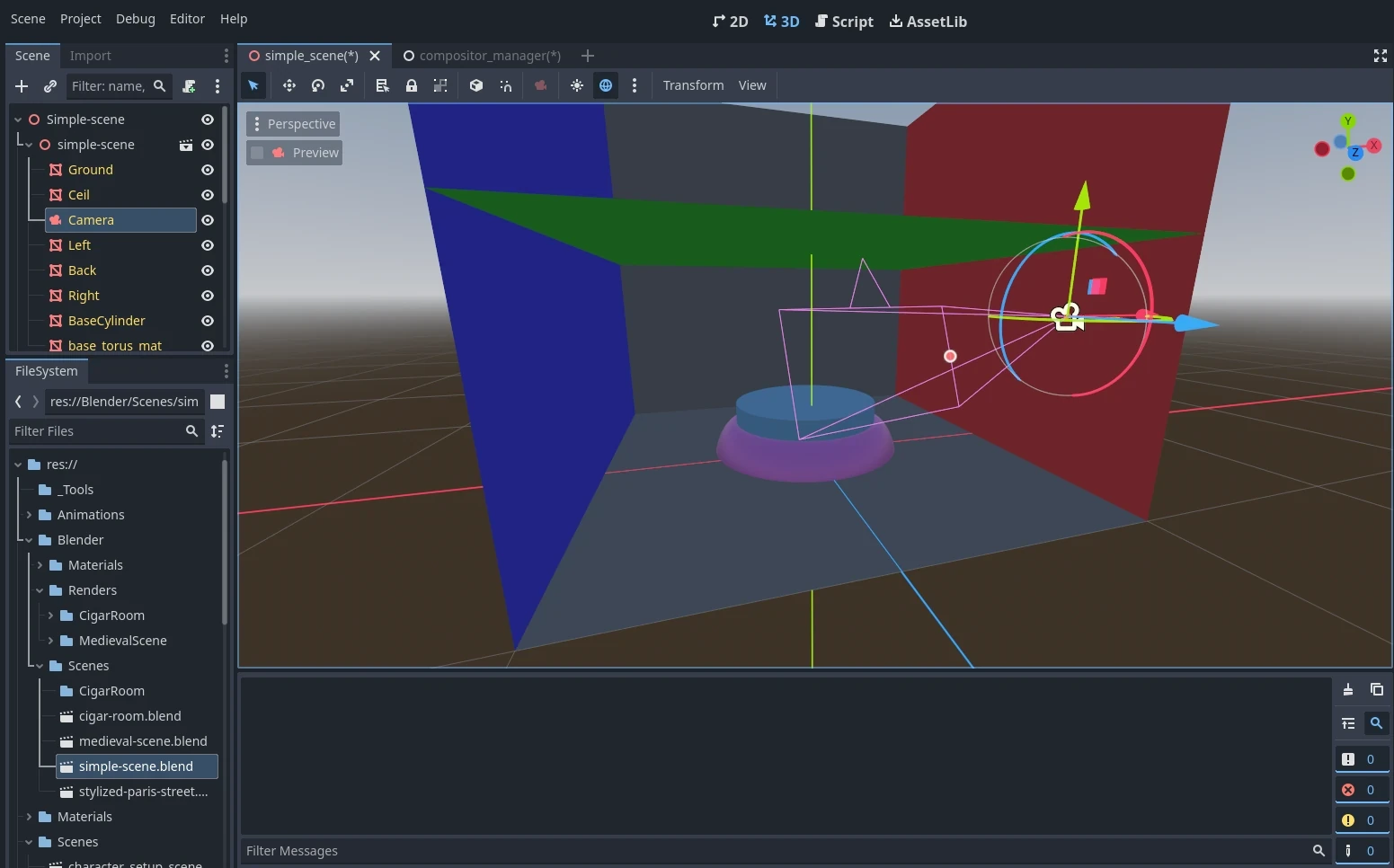
Comme vous pouvez le voir sur les captures, il s’agit d’une Cornell box basique avec un petit podium au centre, sur lequel nous pourrons mettre en scène ce dont nous aurons besoin le moment venu. Dans ce devlog, nous allons nous contenter de mettre en place l’environnement. Il n’y a donc rien sur le podium pour l’instant.
3. Implémentation de l’Oracle
Voyons maintenant de quoi est fait notre oracle. Sans plus de cérémonie, voici son code source. C’est un petit pavé, mais ne vous inquiétez pas, nous allons le décortiquer ensemble.
Vous noterez qu’en l’état, il ne fait pas grand-chose. Voyez ça comme un squelette de base que nous allons habiller petit à petit au fil des devlogs.
shader_type spatial;
render_mode unshaded, fog_disabled;
void vertex() {
POSITION = vec4(VERTEX.xy, 1.0, 1.0);
}
// Type de donnée à comparer
uniform int data_type = -1;
// Determinist & Interactive G-Buffer
const int NB_GMAPS = 1;
uniform sampler2D[NB_GMAPS] d_gbuffer : filter_nearest;
uniform sampler2D[NB_GMAPS] i_gbuffer : filter_nearest;
const vec3 ERROR_COLOR = vec3(1.0, 0.0, 1.0);
// Calcule la différence entre 2 pixels
vec3 compute_difference(vec3 d_frag, vec3 i_frag) {
return ERROR_COLOR;
}
// Point d'entrée du post-process
void fragment() {
vec3 out_color = ERROR_COLOR;
if (data_type >= 0 && data_type < NB_GMAPS) {
// Récupération des pixels déterministe et interactif
vec3 d_frag = texture(d_gbuffer[data_type], SCREEN_UV).rgb;
vec3 i_frag = texture(i_gbuffer[data_type], SCREEN_UV).rgb;
// Calcule de la couleur représentant la différence
out_color = compute_difference(d_frag, i_frag);
}
ALBEDO = out_color;
}
Si c’est la première fois que vous voyez un shader, ce code peut être un peu déstabilisant. Mais ne vous laissez pas intimider ! Il ne vous manque sûrement que quelques éléments de contexte pour êtra à l’aise. Au besoin, vous les trouverez ici.
Maintenant, nous pouvons commencer le tour du propriétaire.
3.1. Code minimal d’un post-process
D’abord, quelques lignes de base qu’on ne détaillera pas complètement (mais un peu quand même). Il s’agit de la façon usuelle de créer un post-process dans Godot.
shader_type spatial;
render_mode unshaded, fog_disabled;
void vertex() {
POSITION = vec4(VERTEX.xy, 1.0, 1.0);
}
Dans ce moteur, le quad sur lequel on va rendre notre post-process est physiquement présent dans la scène (c’est bizarre, mais c’est comme ça). Il faut donc :
- s’assurer qu’il ne reçoive ni la lumière ni le fog :
render_mode unshaded, fog_disabled; - Faire coïncider les coins du quad avec ceux de l’écran dans le vertex shader :
POSITION = vec4(VERTEX.xy, 1.0, 1.0);
3.2. Les uniforms ou paramètres d’entrée
Les uniforms sont les paramètres d’entrée du shader. C’est à travers eux (en partie) que le CPU peut envoyer des données au GPU. Une fois initialisés, ils peuvent être référencés comme des variables globales dans le code du shader.
Les uniforms data_type, d_gbuffer et i_gbuffer correspondent aux deux G-Buffers ainsi qu’au type de données sélectionné pour la comparaison (évoqués précédemment).
// Type de donnée à comparer
uniform int data_type = -1;
// Determinist & Interactive G-Buffer
const int NB_GMAPS = 1;
uniform sampler2D[NB_GMAPS] d_gbuffer : filter_nearest;
uniform sampler2D[NB_GMAPS] i_gbuffer : filter_nearest;
3.3. Calcul de la différence
C’est ici qu’on implémentera le calcul de la différence. Ou devrais-je dire des différences, car comme nous le verrons plus tard, nous serons amenés à traiter les données différemment selon leur type.
const vec3 ERROR_COLOR = vec3(1.0, 0.0, 1.0);
// Calcule la différence entre 2 pixels
vec3 compute_difference(vec3 d_frag, vec3 i_frag) {
return ERROR_COLOR;
}
Pour l’instant, la fonction renvoie simplement ERROR_COLOR, une couleur magenta bien criarde qui attirera immédiatement l’attention si elle apparaît à l’écran.
C’est une technique que j’utilise souvent, qui correspondrait à un throw new Exception(); ou un return -1; en code CPU.
Sur un GPU, la gestion des erreurs est très limitée. Il faut donc parfois être un peu créatif. N’hésitez pas à partager vos petites techniques personnelles dans les commentaires si vous en avez !
3.4. Le point d’entrée du post-process
Et enfin, voici la fonction void fragment(), le point d’entrée principal du post-process.
// Point d'entrée du post-process
void fragment() {
vec3 out_color = ERROR_COLOR;
if (data_type >= 0 && data_type < NB_GMAPS) {
// Récupération des pixels déterministe et interactif
vec3 d_frag = texture(d_gbuffer[data_type], SCREEN_UV).rgb;
vec3 i_frag = texture(i_gbuffer[data_type], SCREEN_UV).rgb;
// Calcule de la couleur représentant la différence
out_color = compute_difference(d_frag, i_frag);
}
ALBEDO = out_color;
}
La première chose à noter, c’est que je réutilise ma technique du ERROR_COLOR d’une manière un peu différente. Ici, je m’assure de la validité du uniform data_type. Si sa valeur n’est pas définie → BOOM ! Écran magenta !
// Point d'entrée du post-process
void fragment() {
vec3 out_color = ERROR_COLOR;
if (data_type >= 0 && data_type < NB_GMAPS) {
// code protégé du fragment()
...
}
ALBEDO = out_color;
}
AYA ! IL A FAIT UN IF QUI SERT À RIEN DANS UN SHADER !
En effet, comme expliqué dans l’article cité en début de section, les branchements conditionnels sont à éviter autant que possible dans le code GPU pour des raisons de performance.
À ma décharge, l’impact ici sera minime, car tous les fragments passent du même côté du if pour un draw call donné. Cependant, il ne faudrait tout de même pas faire ça dans du code de production, car :
- La condition est quand même évaluée.
- La présence du
ifpeut empêcher le compilateur d’effectuer certaines optimisations.
Mais ici, on s’en fout ! On est sur un POC, et l’oracle n’est qu’un outil de développement. La performance n’est pas critique, donc on se permet quelques libertés pour se faciliter la vie.
// Point d'entrée du post-process
void fragment() {
...
// Récupération des pixels déterministe et interactif
vec3 d_frag = texture(d_gbuffer[data_type], SCREEN_UV).rgb;
vec3 i_frag = texture(i_gbuffer[data_type], SCREEN_UV).rgb;
// Calcule de la couleur représentant la différence
out_color = compute_difference(d_frag, i_frag);
...
}
Le reste du code est assez trivial. D’abord, on sample les textures pour obtenir les pixels que l’on souhaite comparer. Puis, on invoque compute_difference(...) sur ces pixels pour déterminer la nuance de gris à afficher.
Part III : Notre première prophétie
Dans ce numéro, nous n’allons pas dérouler l’intégralité du processus d’harmonisation des données. Ce serait beaucoup trop long. Le sujet va nous occuper encore pendant plusieurs devlogs.
D’un autre côté, nous venons de mettre en place un super environnement d’ODD, et il serait terriblement frustrant de ne pas le tester. (Allez ! Juste une fois ! Le prochain épisode n’est pas pour tout de suite…)
Nous allons donc faire ce qu’il faut pour recueillir notre première prophétie. Pour garder les choses simples, nous allons prendre quelques raccourcis et nous limiter à la texture d’albédo (on oublie les autres pour l’instant).
1. Préparation de l’Oracle
Nous allons devoir enrichir un peu le code de l’Oracle pour implémenter la comparaison de l’albédo. Le changement concerne la fonction de calcul de la différence.
Avant :
// Implémentation par defaut qui retournait ERROR_COLOR quoi qu'il arrive
const vec3 ERROR_COLOR = vec3(1.0, 0.0, 1.0);
vec3 compute_difference(vec3 d_frag, vec3 i_frag) {
return ERROR_COLOR;
}
Après :
// Nouvelle implémentation qui prend en compte l'albedo
#define ALBEDO_TYPE 0
const vec3 ERROR_COLOR = vec3(1.0, 0.0, 1.0);
vec3 compute_albedo_difference(vec3 d_frag, vec3 i_frag) {
float dist = distance(d_frag, i_frag);
return vec3(dist, dist, dist);
}
vec3 compute_difference(vec3 d_frag, vec3 i_frag) {
if (data_type == ALBEDO_TYPE)
return compute_albedo_difference(d_frag, i_frag);
return ERROR_COLOR;
}
La fonction compute_difference(...) ne renvoie plus systématiquement ERROR_COLOR. Lorsque le type de données à comparer est réglé sur ALBEDO_TYPE, la fonction compute_albedo_difference(...) est invoquée à la place. Elle effectue une simple distance euclidienne entre les deux couleurs.
2. Assignation des textures
La génération des textures d’albédo déterministe et interactive est malheureusement hors scope pour aujourd’hui. On va simplement considérer qu’on les a déjà et qu’elles ont été obtenues à partir d’un Godot et d’un Blender dans leur paramétrage d’usine, sans toucher à plus que le strict nécessaire. Les voici :
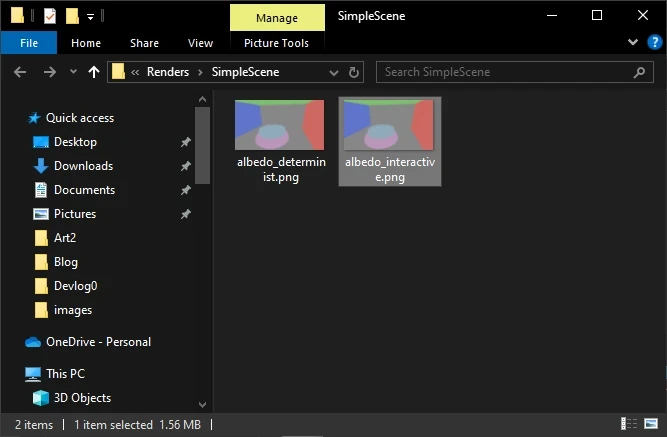
À partir de là, il ne reste plus qu’à les assigner aux uniforms correspondants dans oracle.gdshader et à régler data_type sur 0 (qui correspond à ALBEDO_TYPE).

3. C’est maintenant ! C’est maintenant !
Le type de données à comparer est bien réglé sur Albedo. Nos textures sont en place, correctement générées (faites-moi confiance…) et associées aux uniforms du shader. Elles proviennent de deux scènes rigoureusement identiques issues du même fichier. Si l’importeur de Godot a bien fait son travail en traduisant les données de Blender, nous devrions obtenir une prophétie rassurante… c’est-à-dire un bel écran noir.
Qu’est-ce qui pourrait mal se passer ?

Oh nooo !!!
Quelle surprise ! L’image n’est pas noire (qui aurait pu s’en douter ?!). Rassurez-vous, l’importeur fonctionne très bien, le problème vient d’ailleurs. Il va falloir trouver ce qui cloche et le corriger. Mais ce sera pour une autre fois, car nous arrivons à la fin de ce devlog. (Oui… je dois garder un peu de temps pour le dev, sinon il n’y aura plus rien à raconter.)
Conclusion :
Nous venons de poser les bases d’un environnement capable de comparer facilement les données produites par Blender et Godot. Jusqu’ici, il ne nous a appris qu’une chose : ces données ne sont pas compatibles par défaut (en ce qui concerne l’albédo au moins).
C’est à partir de là que le vrai travail va commencer. Par le biais de différents réglages et pré-traitements, d’un côté comme de l’autre, nous allons harmoniser les deux logiciels. Mais nous ne ferons pas ça à l’aveugle. Grâce à l’Oracle, nous aurons un moyen efficace de visualiser l’impact de nos ajustements. Itération après itération, nous pourrons garder ce qui améliore les résultats et jeter le reste. Et ce, jusqu’à obtenir des données totalement identiques (du moins, c’est ce qu’on espère).
Cependant, notre unique scène de test reste très simpliste. Même lorsque nous aurons des écrans totalement noirs pour toutes les valeurs de data_type, ce ne sera pas forcément suffisant. Pour être vraiment sûrs que Godot et Blender sont bien en phase, il faudra plus de données, et surtout des données plus complexes.
Pas de panique, c’est prévu ! Godot comprend les .blend et nous avons désormais un Oracle dans l’équipe. Il sera donc relativement facile de mettre à l’épreuve de nouvelles scènes au fur et à mesure de l’avancement du projet. Et chaque fois que de nouvelles dissonances apparaîtront, on rouvrira le dossier.
Le mot de la fin
Je terminerai en disant que ce devlog a été assez compliqué à écrire. J’ai perdu beaucoup de temps à me remémorer les choses et à les reconstituer. Malheureusement, ce sera comme ça tant que je n’aurai pas fini de recoller les wagons (prenez soin de votre Git, les amis…).
Mais reconnaissons quand même un avantage à la situation : le TurboTartine du futur, malgré ses problèmes de mémoire, sait à peu près ce qu’il a fait ensuite, ce qui aide à structurer tout ça.
D’ailleurs, je peux déjà annoncer le sujet du prochain numéro ! Dans le prochain devlog, nous allons utiliser l’oracle pour harmoniser les textures d’albédo de nos G-Buffers (qui l’eût cru hein ?).
D’ici là, prenez soin de vous, et j’espère que ce premier devlog vous aura plu. N’hésitez pas à me faire vos retours !
comments powered by Disqus